This week in programming we have learnt about Binary Search Trees (BST). While creating the program for a BST recursion is a great method to know and to use. Recursion is when a method calls itself from inside. You can read more about it on wikipedias page about recursion: http://en.wikipedia.org/wiki/Recursion_%28computer_science%29
I thought I could go through how I wrote my code to find the node to erase in the tree and why I chose to do it in that way. Let’s begin with the parameters; I send in a generic value – the value of the node that I want to erase, and two nodes. The first node is the one the function should check if it’s the one to erase and the second is the node the function checked the last time. Why I want the parent node is for when I erase a node I need to change the pointer pointing at it from its parent. I won’t explain how I erase the nodes in this blogpost since that isn’t really relevant to the recursion. And if you really want to know more about BSTs and how you remove nodes you can read about it in this Wikipedia page: http://en.wikipedia.org/wiki/Binary_search_tree

The first time this method is called the first node is the root node – the node that is in the top of the tree, before this method is called I check that there actually is a root node else the tree is empty and there are no nodes to erase. And the second node is a null pointer since there is no node pointing to the root.
The first thing I check is that the node to check is not a null pointer since that would mean the function has reached the end of the tree and has not found the right value. If that happens I return false so the recursion will stop and this false will tell my program that the value was not found and it will write in the console something like “That value was not found, try again”.
If the node is not a null pointer I check if it’s value is the one I was looking for. If it was not I check if the value I am searching for is bigger or smaller than this nodes value. If it is bigger I call the function again sending the same value to find, the current nodes bigger child to be checked and the current node as the parent. If it’s smaller I send the smaller child instead of the bigger one. And the function starts from the beginning with the new parameters.

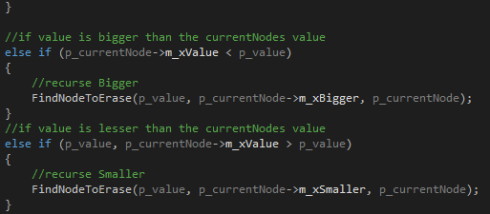
But if a node with the right value is found I have to check how many children it has. If it has one or no child I call another function to remove them and then I return true telling my program that the node was found and erased and it writes something like “The value was found and erased” in the console. And the recursion is done
.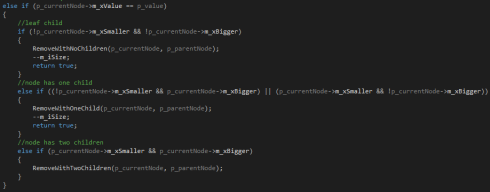
But what I have done if the node has two children is to call a function that finds the value to replace the current nodes value with then change its value, and then I call the previous function again. But this time I send in the value of the node which value I copied to be found and erased, the node that is the current nodes smaller child to be checked and the current node as the parent. I don’t start looking from the top again because firstly it would be unnecessary since I know the node to erase is under this node, and secondly because the node found would only be the same node again since they have the same value.
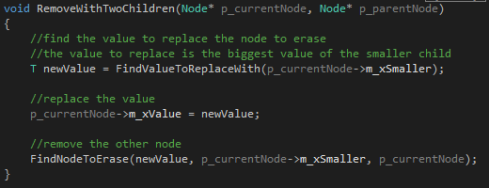
When the previous function finds this value it will erase it as a node with one or no children! (If you don’t understand why, look at the second Wikipedia page I linked in the beginning.)







